
Mantenimiento predictivo industrial
Cuando un motor crítico empieza a desviarse, casi nunca lo hace con una única señal aislada. Lo hace alterando el equilibrio entre carga, vibración, temperatura, corriente, régimen, contexto operativo y comportamiento histórico. Ahí es donde el anomaly detection multivariable deja de ser una promesa técnica y se convierte en una herramienta real para evitar paradas no planificadas.
El objetivo no es lanzar alertas por cualquier ruido. El objetivo es distinguir qué cambio merece atención, con qué urgencia y bajo qué condiciones de operación. Si el modelo aprende el patrón normal del motor y entiende sus relaciones internas, puede detectar degradaciones sutiles mucho antes de que se conviertan en avería, planificar la intervención y proteger la producción sin sobrerreaccionar.
Qué vas a sacar de este artículo
- Qué diferencia un modelo multivariable serio de un sistema que solo dispara alarmas sueltas.
- Qué señales de motor conviene combinar para detectar degradación temprana sin inflar falsos positivos.
- Cómo diseñar un flujo operativo que convierta la alerta en decisión útil y no en otro dashboard más.
- Qué KPIs debes seguir para demostrar que el sistema evita paradas y no solo “predice anomalías”.

Guía inicial para enfocar bien el caso de uso
Elige el motor correcto
Prioriza activos cuya parada detenga producción, degrade calidad, fuerce retrabajo o tenga coste alto de intervención urgente.
Mide contexto, no solo señal
Temperatura o vibración sin carga, velocidad, receta, turno o régimen operativo pueden llevar a conclusiones erróneas.
Aprende el patrón normal
El modelo debe entender cómo se comporta el motor cuando está sano en distintos escenarios, no solo cuándo falla.
Conecta la alerta con una acción
Sin severidad, ventana sugerida e hipótesis técnica, la detección pierde valor operativo y la adopción cae rápido.
Por qué los motores concentran tanto riesgo operativo
En muchas plantas, los motores son el punto donde convergen disponibilidad, estabilidad de proceso y coste de mantenimiento. Un fallo puede detener bombas, ventiladores, cintas, compresores, agitadores, extrusoras o sistemas auxiliares que parecen secundarios hasta que dejan de responder.
El problema no es solo la avería final. El verdadero coste suele empezar antes: consumo anómalo, pérdida de eficiencia, vibración creciente, degradación de rodamientos, sobrecarga, calentamientos repetidos o trabajo fuera de la envolvente ideal. Todo eso erosiona fiabilidad y deja una ventana de actuación que muchas veces se desaprovecha.
Impacto directo en producción
Un motor crítico rara vez falla “solo”. Suele arrastrar cuellos de botella, cambios de secuencia, esperas de mantenimiento y riesgo de incumplimiento.
Patrones de fallo poco obvios
Muchas degradaciones no se ven con un umbral fijo. Aparecen cuando varias señales dejan de correlacionarse como deberían.
Precisamente por eso el mantenimiento predictivo en motores encaja muy bien dentro de una estrategia más amplia de mantenimiento predictivo en la industria: no se trata de monitorizar por monitorizar, sino de proteger decisiones operativas concretas.
Qué aporta el anomaly detection multivariable frente al enfoque clásico
El enfoque clásico suele trabajar con reglas separadas: vibración por encima de un umbral, temperatura alta, corriente fuera de tolerancia o alarmas del variador. Eso ayuda, pero llega corto cuando el problema se manifiesta como una combinación de pequeñas desviaciones. El anomaly detection multivariable busca justo ahí.
En vez de preguntar “¿está esta variable fuera de rango?”, pregunta “¿se está comportando este motor como debería dadas sus condiciones actuales?”. Esa diferencia cambia la calidad de la alerta.
| Enfoque | Cómo observa el motor | Punto fuerte | Límite habitual |
|---|---|---|---|
| Umbral fijo | Evalúa una variable de forma aislada. | Es simple y rápido de implantar. | Genera ruido cuando cambia la carga o el contexto operativo. |
| Modelo univariable | Detecta tendencia anómala en una señal concreta. | Sirve para problemas muy conocidos. | No capta interacciones entre variables. |
| Anomaly detection multivariable | Aprende relaciones normales entre varias señales y contexto. | Detecta degradación sutil y contextual. | Requiere mejor trabajo de dato, validación y puesta en operación. |
Este enfoque encaja especialmente bien cuando hay poca etiqueta histórica de fallo o cuando el activo cambia de régimen con frecuencia. Una revisión reciente sobre mantenimiento predictivo basado en machine learning destaca precisamente el crecimiento de métodos no supervisados y de anomaly detection cuando las etiquetas de fallo son escasas o poco fiables: Application-Wise Review of Machine Learning-Based Predictive Maintenance.
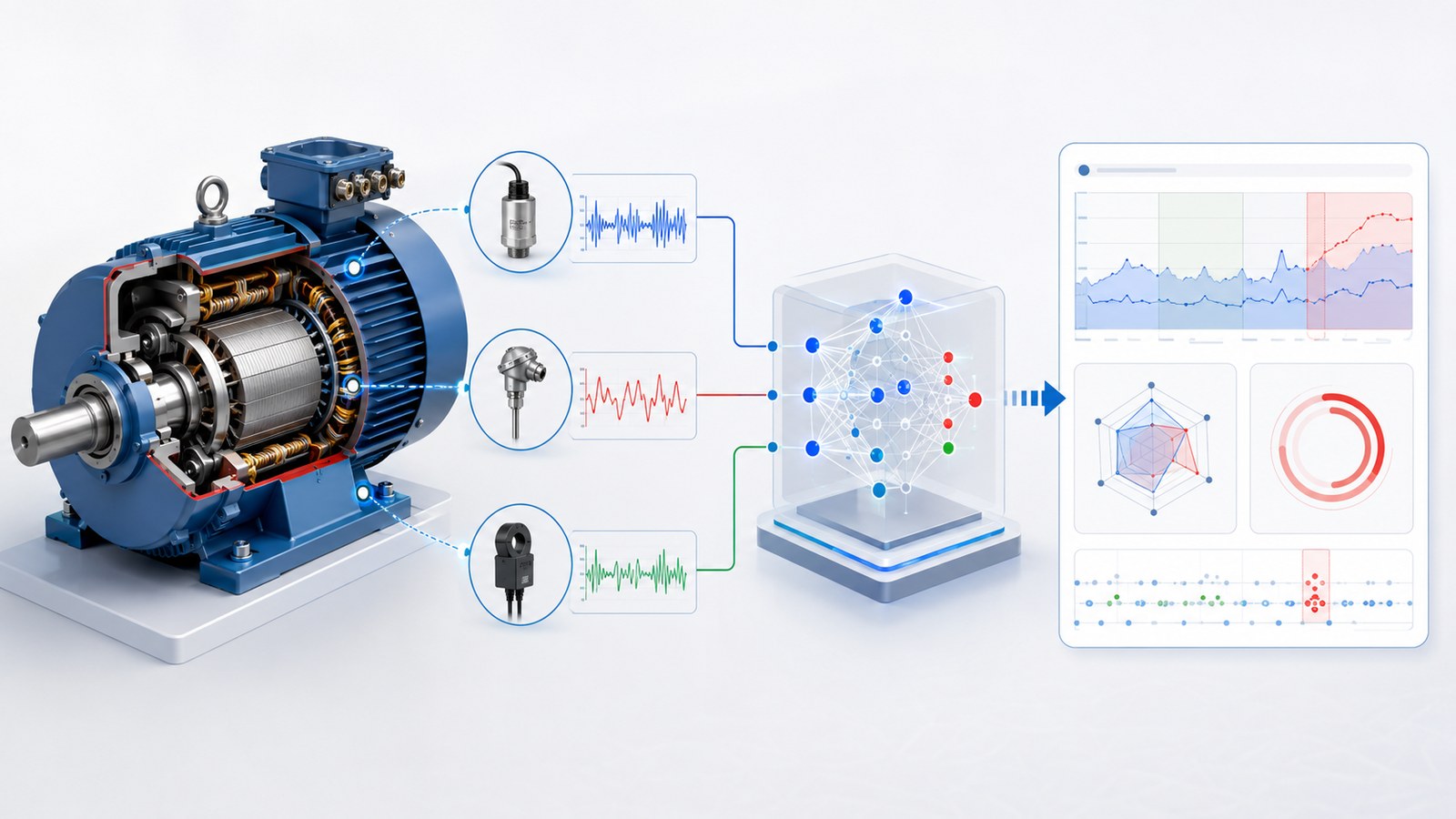
Qué variables conviene combinar en un modelo multivariable de motores
No existe una lista universal. La combinación correcta depende del tipo de motor, del accionamiento, del proceso y del nivel de instrumentación disponible. Aun así, suele haber un núcleo de señales especialmente útil:
Variables eléctricas
Corriente, tensión, potencia, factor de potencia, desequilibrio de fases o armónicos ayudan a detectar sobrecarga, desalineación funcional y degradación eléctrica.
Variables mecánicas
Vibración RMS, espectro, velocidad, aceleración o patrones de frecuencia son clave para rodamientos, holguras, desbalanceos y defectos incipientes.
Variables térmicas
Temperatura de carcasa, devanados, rodamientos o armario eléctrico aportan contexto sobre fricción, sobrecarga, ventilación y esfuerzo sostenido.
Variables de contexto
Carga de proceso, consigna, receta, presión, caudal, turno, ambiente y estado del variador evitan interpretar como fallo lo que solo es un cambio operativo.
La clave no es meter muchas señales, sino elegir las que realmente explican el comportamiento normal del activo. En un entorno de Industria 4.0 e IA industrial en planta, el salto de valor aparece cuando estas señales se integran con criterio y se traducen en una decisión clara para mantenimiento u operaciones.
Cómo funciona una arquitectura útil en planta
Un sistema operativo de anomaly detection multivariable para motores suele apoyarse en cuatro capas. Si una falla, el modelo puede ser correcto en laboratorio y poco útil en planta.
- Captura y sincronización. Las señales deben quedar alineadas en tiempo, con calidad suficiente y sin perder eventos relevantes por frecuencia de muestreo inadecuada.
- Contextualización. El modelo necesita saber en qué estado trabajaba el motor: arranque, carga estable, transición, parada, cambio de receta o limpieza.
- Modelado de normalidad. El algoritmo construye un espacio de comportamiento sano para detectar desviaciones por distancia, reconstrucción, densidad o score de rareza.
- Orquestación operativa. La alerta debe llegar con severidad, evolución, hipótesis y recomendación de siguiente paso, idealmente integrada con GMAO, SCADA o flujo de trabajo de mantenimiento.
Cuando esta arquitectura se despliega bien, la alerta deja de ser un susto y pasa a ser una herramienta de priorización. Ese es el punto donde de verdad empieza a ayudar a prevenir paradas no planificadas y ahorrar dinero.
De la alerta a la intervención: qué debería ver el equipo
Un buen modelo no termina en un score. Tiene que ayudar a decidir. Por eso la salida operativa debería responder, como mínimo, a estas preguntas:
- Qué tan anómalo es el comportamiento respecto al patrón normal del motor en ese contexto.
- Qué variables explican la desviación y cómo han cambiado en las últimas horas o días.
- Si la anomalía está creciendo, estabilizada o intermitente, porque eso afecta la urgencia.
- Qué acción tiene sentido ahora: inspección, lubricación, revisión de alineación, verificación eléctrica, seguimiento intensivo o intervención programada.
Sin este aterrizaje, el riesgo es conocido: una colección de alertas que el equipo acaba ignorando. En cambio, si la señal llega con contexto y trazabilidad, la conversación cambia de “hay una alarma rara” a “tenemos una desviación consistente, con impacto potencial y ventana razonable para actuar”.
Beneficios reales cuando el sistema está bien diseñado
Menos urgencias improductivas
La detección temprana permite mover trabajo de correctivo urgente a mantenimiento planificado, con mejor seguridad y menor impacto en producción.
Menos falsos positivos operativos
Al incorporar contexto de carga y proceso, el modelo distingue mejor entre variación normal y degradación real.
Mayor vida útil del activo
Intervenir en fase incipiente evita que pequeños defectos escalen hacia fallo de rodamiento, bobinado, acoplamiento o sistema asociado.
Mejor conversación entre mantenimiento y operaciones
La decisión deja de apoyarse solo en intuición o urgencia del momento y se apoya en evidencia operativa más consistente.
Errores que suelen frenar el retorno
Modelar sin separar modos operativos
Un mismo motor no “es normal” igual en arranque, carga parcial y plena carga. Mezclar todo degrada la calidad de la detección.
Ignorar calidad y sincronía del dato
Huecos, desalineación temporal y cambios de escala pueden parecer anomalías cuando en realidad son problemas de adquisición.
Querer predecir fallo exacto desde el día uno
En muchos casos es mejor empezar detectando desviación útil y construir luego diagnóstico más fino, en vez de prometer una taxonomía perfecta de averías.
No definir quién actúa ante cada severidad
Sin protocolo de respuesta, la calidad del modelo importa menos de lo que parece porque la alerta no se convierte en impacto.
Cómo empezar con un piloto serio sin caer en un experimento eterno
El mejor primer despliegue suele ser un conjunto pequeño de motores críticos, con datos suficientes y una ventana operativa donde la intervención pueda planificarse. No hace falta empezar con toda la planta. Hace falta empezar con una pregunta que tenga retorno claro.
- Selecciona entre 3 y 10 motores con impacto real. Mejor pocos y relevantes que muchos sin dueño operativo.
- Define claramente qué evento quieres evitar. Parada total, degradación de rendimiento, fallo repetitivo o sobrecoste de mantenimiento.
- Asegura lectura conjunta entre mantenimiento y proceso. La anomalía debe interpretarse también desde el contexto productivo.
- Mide precisión operativa, no solo calidad estadística. Interesa saber cuántas alertas útiles generó, con qué antelación y con qué decisión resultante.
- Documenta las condiciones de réplica. Si el caso funciona, deja claro qué datos, frecuencias y reglas de actuación necesitas para escalar.
KPIs que sí te dicen si el proyecto está evitando paradas
Cuánto tiempo antes de la intervención o del fallo apareció una señal realmente accionable.
Porcentaje de alertas que derivaron en revisión, corrección o decisión justificada.
Si el modelo sirve, debería caer el peso del mantenimiento reactivo no planificado en esos activos.
Horas de paro evitadas, estabilidad del proceso y menor pérdida asociada a degradación no detectada.
Preguntas frecuentes
¿Hace falta tener muchos fallos históricos para empezar?
No necesariamente. De hecho, el anomaly detection multivariable suele ser útil precisamente cuando hay pocos fallos etiquetados. Lo importante es disponer de suficiente histórico de operación normal y contexto operativo bien capturado.
¿Sirve con motores ya instrumentados o hay que añadir muchos sensores?
Depende del activo y del riesgo que quieras cubrir. Muchas veces ya existe una base suficiente con variables eléctricas, velocidad, temperatura y datos de proceso. Los sensores adicionales deben añadirse donde aumenten realmente la capacidad de distinguir degradación temprana.
¿El modelo sustituye al técnico de mantenimiento?
No. El modelo ordena señal, anticipa desviaciones y ayuda a priorizar. La decisión final sigue necesitando criterio técnico, conocimiento del activo y lectura del contexto de planta.
¿Cuál es la señal de que el proyecto va bien?
Que las alertas se vuelven parte de la rutina operativa, que el equipo confía en ellas porque entiende su contexto y que empiezan a desplazarse intervenciones desde la urgencia hacia la planificación.
Cierre estratégico
El mantenimiento predictivo de motores basado en anomaly detection multivariable no consiste en poner IA encima de un motor y esperar magia. Consiste en modelar con rigor cómo debería comportarse ese activo en su contexto real, detectar cuándo deja de hacerlo y traducir esa desviación en una decisión rentable.
Cuando se hace bien, el resultado no es un dashboard más. Es una operación menos reactiva, un mantenimiento mejor priorizado y una planta más protegida frente a paradas no planificadas que hoy todavía llegan demasiado tarde.